C.Serge de Souza
desouza@computing.edu.au 09953174 CP352
Sound Samples
 hello_this_is_a_voice_with_an_accent.wav
hello_this_is_a_voice_with_an_accent.wav
hello_this_is_a_voice_with_an_accent_weak_br_accent.wav
hello_this_is_a_voice_with_an_accent_strong_br_accent.wav
he_measured_the_length_of_the_chain.wav
he_measured_the_length_of_the_chain_weak_br_accent.wav
he_measured_the_length_of_the_chain_strong_br_accent.wav
long_sentence.wav
long_sentence_weak_br_accent.wav
long_sentence_strong_br_accent.wav
news.wav
news_weak_br_accent.wav
news_strong_br_accent.wav
no_one_knew.wav
no_one_knew_weak_br_accent.wav
no_one_knew_strong_br_accent.wav
the_beans_were_delicious.wav
the_beans_were_delicious_weak_br_accent.wav
the_beans_were_delicious_strong_br_accent.wav
1-Introduction 3
2-Background 4
2.1-Accents 4
2.2-Talking
Head 6
2.3-XML 8
3-Implementation 10
3.1-Overview 10
3.2-SML
extension 11
3.3-Accent
Module 12
3.3.1-Basic
Procedure 12
3.3.2-Alternatives 13
3.3.3-Information
on phonemes 14
3.3.4-Detailed
Procedure 14
3.3.5-Accent
intensity 15
3.3.6-MRPA
and SAMPA 16
3.4-Integration
to the Talking Head 16
4-Testing and Analysis 18
4.1-Testing 18
4.2-Test
Data 18
4.3-Analysis
and results 19
4.4-Known
Faults 19
4.4.1-Synchronisation 19
4.4.2-Possible
problems 20
5-Future Work 21
5.1-Different
database for Portuguese 21
5.2-Different
Accent 21
5.3-Integration 21
5.4-Grammar 21
6-Conclusion 22
7-Reference List 23
8-Appendix A: Phonemes in br1 25
9-Appendix B: Phonemes in en1 31
10-Appendix C: Mapping of Phonemes from en1 to
br1 42
11-Appendix D: Code Modifications 44
Acknowledgements
I would like to thank my friends Alan, Daniel, Kamila, Kate,
and Kheng, (I hope I am not forgetting anyone) and also Fabricio for
helping me evaluate the final results of my project. Sarah for her
efficiency in getting the book by Azevedo which was one of the bases
of my project, and for helping me keep it for nearly the whole year.
And all those who showed concern and interest in the progress of my
project.
Thank you also to Mike Hamilton for making available all the
information for adding accents to text to speech systems and to
Ricardo Schutz for providing the reference to the Azevedo book, and
to both of them for answering Email and providing useful information
to a total stranger.
And
last, but definitely not least, I would like to thank my project
supervisor Andrew Marriott for his time, his patience, and
perspicacity. I would also like to thank him for demonstrating
interest in my project all year long and for providing a comfortable
and friendly working environment with tools and resources that were
important to the development of my project.
Introduction
Humans use languages to communicate and are able to speak several
languages, but often languages that are not their first language,
suffer some variations that we name accent. Current text to speech
technology allows the production of speech that closely resembles
that of a human. Is it possible to introduce an accent in current
text to speech synthesis systems ?
This report will present some of the background information
relating to several aspects of the project. The report will also show
how the problem of adding a n accent to a text to speech system with
different levels of intensity was approached, how it was tested, the
results obtained, and how the accent module was integrated to a
talking head using XML.
A section containing a number of indications on how this project
could be improved or what other projects could be derived from it is
included towards the end of the report.
Background
Accents
The performance of Text to Speech Synthesis Systems (TTS) is
constantly improving. It is possible to modify many of the properties
of the sound produced in order to make it more understandable and
more realistic. Prosody is "the rhythmic and intonational aspect
of language"(www.yourdictionary.com Homepage, 2000) and helps
improve the realism of the sentences produced by a TTS system. Many
TTS tools allow the integration of prosody either prior to the
generation of the sound file or after. The Elan Speech Cube allows
the use of Prosel, which is a tool that applies a prosodic contour to
the sound file after it has been generated by the synthesiser. The
Festival TTS is much more powerful and allows a modification of
several features such as duration, pitch, and intonation. It also
allows the definition of extra letter to sound rules, these define
how the words are going to be read by the Natural Language Parser
(NLP). There are also more crude NLPs, such as ttp_p.pl by Luis Alves
for Portuguese, that are simple PERL scripts and offer little or no
options for modifying the output and require the use of the "-e"
option for ignoring errors when MBROLA is run.
The TTS system used for this project is made of two components, on
the one hand the NLP and on the other the Digital Signal Processor
(DSP). The NLP used is FESTIVAL and the DSP is MBROLA. The NLP can be
considered as a person's brain, it looks at the words and figures out
what are the sounds that they contain using prior knowledge of the
word or letter to sound rules if the word is unknown. Once this is
done, it is up to the vocal tract to emit the sounds, this is the
role played by the DSP.
MBROLA is
"a
speech synthesizer based on the concatenation of diphones. It takes a
list of phonemes as input, together with prosodic information
(duration of phonemes and a piecewise linear description of pitch),
and produces speech samples on 16 bits (linear), at the sampling
frequency of the diphone database used (it is therefore NOT a
Text-To-Speech (TTS)synthesizer, since it does not accept raw text as
input).It is thus more suitable to define Text-To-Speech as the
automatic production of speech, through a grapheme-to-phoneme
transcription of the sentences to utter." (Mbrola Homepage,
2001).
The NLP produces phonemes, "an abstract linguistic unit
[that] is the smallest meaningful contrastive unit in a language. It
is thus neither defined on an acoustic nor physiological basis but on
a functional one" (Dutoit, 1997, p8). Each language has it's own
set of phonemes, for example Schutz (2001a, 2001b) distinguishes
seven vowel phonemes and nineteen consonant phonemes in Portuguese as
opposed to eleven vowel phonemes and twenty-four consonant phonemes
in English. A person whose first language is Portuguese will find it
harder to pronounce phonemes that are not part of his/her initial
phonemic vocabulary, moreover when we say that there are seven vowel
phonemes in Portuguese and 11 in English this does not mean that the
Portuguese vowels are a subset of the English vowels. If the number
of common phonemes between the two languages is small, it will be
harder for a Portuguese speaker to speak English, from a
pronunciation point of view. This is due to what is called L1
interference or the interference of the speaker's first language with
the second language and is referred to as "negative transfer of
the structures and patterns of one first language to the second
language" (Major, 1987, p.185). Basically the speaker tries to
pronounce an English sentence using his/her first language habits.
Linguists also recognise other factors as being the cause of people
speaking with an accent the more important ones are age,
developmental factors and style.
The age argument recognises that the "older learners have
difficulty learning how to speak a foreign language without an
accent" (Major, 1987, p.185). Major (1987, p.186) citing Scovel
(1969) "claims that learning native pronunciation in a foreign
language after puberty is impossible", but Hill (1970), also
cited in Major, claims that it is possible provided the "affective
and cultural factors are present".
The developmental factors argument involves the cases where the
accents and mistakes made are comparable to those made by a child
learning a language or those that cannot be linked directly to L1
interference (Major, 1987, p.190). These include improvisation of
sounds in languages that the person has never heard or knows little
about, the speaker replaces the natural sound with an incorrect sound
that cannot be justified by L1 interference.
The style factor argument is when the speaker adapts the speech to
the context. For example the person will mispronounce a word in
speech but will be capable of reading it from a word-list. Another
case is that of a person fluent both in L1 and L2, whilst speaking to
L1 monolingual individuals, this person will pronounce L2 words with
the same mistakes as these individuals, but in company of L2 native
speakers, will pronounce these same words correctly (Major, 1987,
p.192).
L1 interference is the most commonly accepted cause of accents and
was the foundation of what is now known as Contrastive Analysis.
However L1 interference by itself cannot explain all of the errors
made (Major, 1987, p.187). This theory has progressed and it is
possible according to Azevedo (1981, pp. 6-7) citing Lado (1968,
pp.124-125) to "predict probabilistically many of the
distortions that a speaker of L1 is most likely to introduce into L2
as he learns it [...] the inventory of distortions does not represent
behaviour that will be exhibited by every subject on every trial. It
represents behaviour that is likely to appear with greater than
random frequency, and it represents the pressures that have to be
overcome " by the speaker of a foreign language.
Talking Head
The talking head (TH) is a virtual 3D computer animated head that
is being developed in collaboration with a consortium of 11
Universities and organisations as a part of the Interface project
(Interface Homepage, 2001). The talking head is meant to simulate a
human being using various audio and video tools. The use of these
tools is aimed at making the talking head seem more natural and thus
facilitate communication with a human being. These tools include
OpenGL, MPEG-4, VHML the Virtual Human Markup Language (VHML
Homepage, 2001), which includes SML the Speech Markup Language; it
also makes use of artificial intelligence and of a text-to-speech
synthesiser (TTS). The TH may be used in a wide range of
applications, such as an interactive news reader, an overseas news
correspondent, a storyteller, a mentoring system (Mentor Homepage,
2001), a virtual lecturer or a virtual salesperson. The TH is capable
of expressing emotion through facial expression using facial
animation parameters (FAP), that modify the geometry of the face.
This feature is supported by the Facial Animation Markup Language
(FAML). A texture map can also be applied to the TH, providing it
with greater resemblance with the given individual from whom the
texture map was derived (Tschirren, 2000). This feature improves the
realism of the TH.
The TTS module is considered as a black box; it allows the TH to
speak using text provided by the brain. The TTS synthesiser
"comprises a natural language processing (NLP) module, capable
of producing a phonetic transcription of the text to be read,
together with the desired intonation and rhythm, and a digital signal
processing (DSP) module, which transforms the symbolic information it
receives into natural-sounding speech" (Dutoit, 1997, p.14). The
TH currently produces emotive speech using SML (Stallo, 2000). The
output from the (NLP) is modified before it is supplied to the (DSP)
in order to obtain the desired emotion in the output voice. This is a
significant improvement from the blank neutral voice of the
synthesiser that now makes the TH sound more natural.
It is necessary to add some personality to the TH; the fact that
it can be made to resemble an existing person and that it can express
emotion through facial expression and speech are important
improvements. If the TH was required to represent a foreigner we
could add a texture map representing a person of whichever ethnicity
we wanted, but there would be a problem in regards to the voice.
Currently the TH only allows for a pure English voice (or any other
language supported by the TTS synthesiser). Thus if we were
representing an ethnic person we would have to use a pure English
voice, which would not always be appropriate. It would be better if
we had the option of using a voice with an accent because this would
increase the number of applications and also the realism of the TH.
XML
The TH uses VHML (VHML Homepage, 2001), some modifications were
made in order to allow the TH recognise marked-up text that is to be
produced with an accent. In particular the speech markup language
(SML) was modified. SML is a markup language described by the
Extensible Markup Language (XML). XML is a meta language and is used
to describe the content of a document. It is very powerful in that it
can be easily extended, new tags can be added and will normally blend
in nicely with the existing tags. All XML documents have as part of
their header a declaration specifying that they are XML documents
followed by a reference to their grammar, which is called a Document
Type Definition (DTD), modifications can be easily made to this
document.
For Example:
<?xml version="1.0">
<!DOCTYPE sml SYSTEM "./sml-v01.dtd">
XML documents all follow a strict structure, and are validated
against the DTD, any document that does not conform to the DTD is not
accepted and must not be processed any further. XML documents are
plain text documents in order to ensure portability but also
readability, they can thus be easily viewed or modified using a
simple text editor. An XML document can contain any data type as long
as it is supported by the corresponding DTD, therefore it is possible
to integrate sound as well as video or images in an XML type
document.
The XML document is parsed by a program using libxml, jaxpl
(JAVA). There are two solutions for parsing the document, one is
using events, which requires the use of the Simple API for XML (SAX)
and the other is to use a Document Object Model (DOM) that will
represent the document in a tree like structure. SAX has the
advantage of being able to parse large documents; when a tag that is
of interest to a given program is found an event is fired that
notifies the program of the occurrence of this tag. The DOM
represents the whole XML document as a tree that is stored in memory,
each node represents a tag present in the document, information can
then be extracted from these nodes in order to be processed according
to their type of content.
Implementation
Overview
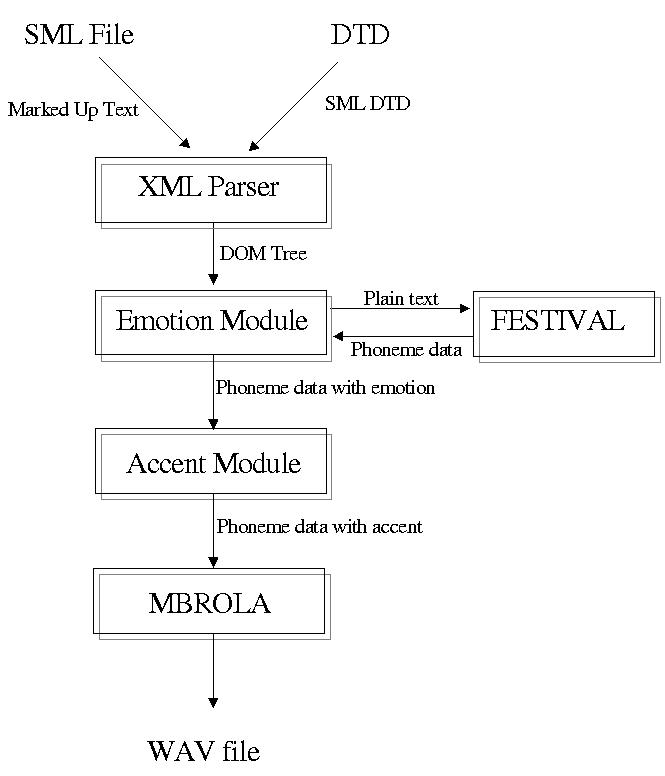
Illustration
1 Integration of the accent module
Illustration 1 shows how the accent module will
be added to the existing TH. An SML file is parsed using its'
respective DTD by the XML parser. The SML document contains tags that
specify what type of emotion is to be applied to the different
sections of marked up text. The emotion module sends the text to
FESTIVAL, the NLP, which returns the corresponding phonemes along
with the duration and pitch of the phonemes. The emotion module then
modifies the pitch, or the duration of the phonemes depending on
the desired emotion (Stallo, 2000).
Once emotion has been added, the accent module receives the
modified phonemes and modifies them further, preserving the emotional
aspects of the utterance. The modifications that are applied are
described in the following sections. Once the modifications have been
applied, the phoneme data is passed to the DSP which then creates the
WAV file.
At the start of the project it was intended for the ELAN
INFORMATIQUE TTS system, named Speech CUBE, to be used. ELAN being
part of the Interface Group involved with the TH, it appeared more
adequate to use their product rather than any other system. The
Speech CUBE is a commercial TTS system and it's output is of good
quality, but unfortunately it is not possible to separate it into an
NLP and a DSP and obtain the phonemic output of the NLP, this is
essential in order to be able to modify the characteristics of the
output, therefore the more flexible FESTIVAL+MBROLA combination was
used.
SML extension
In order for the accent module to be used, the text being included
must be marked up with the appropriate tag. An investigation was
performed in order to find an existing tag that conformed in some way
to a standard. The MPEG-7 standard, also known as the "Multimedia
Content Description Interface" does not contain a descriptor for
an accent, there exists a descriptor for the language of the content
of the media described, but nothing for accents (Multimedia
Description Schemes Group,2001). Therefore a new tag was required.
The accent depends on the speaker, therefore the accent property
was implemented as an extension of the speaker tag. The speaker tag
received two more attributes, one for specifying the type of accent
and another for specifying the intensity of the accent to be
implemented. The DTD was modified as follows in order to support
these changes:
<!ELEMENT speaker (#PCDATA |
%LowLevelElements;)*>
<!ATTLIST
speaker
gender
(male | female) "male"
name
(en1 | us1) "en1"
accent (brazilian | english) "english"
accentint (low | high) "low">
Therefore if we were to markup some text we would submit the
following input:
<speaker gender="female"
name="en1" accent="brazilian" accentint="low">
Hello this is a female voice with a Portuguese accent</speaker>
Accent Module
Basic
Procedure
If we recall the analogy of a TTS to a human in the background
section on accents, along with the linguistic theories relating to
the existence of accents we could use this in the implementation of
the accent module. The NLP is the brain of the person and will read
the text, this will be done following the pronunciation rules of the
language being spoken, in our case English. A person to whom English
is a second language will have good knowledge of the pronunciation
rules, difficulties will arise when the person will try to pronounce
the words. The vocal tract may not be used to pronouncing sounds that
are absent from the speakers first language thus causing distortions
to the output. For these reasons we derived that a NLP that produces
phonemes that correspond to the pronunciation of a native English
speaker was required. We then needed a way to simulate the output of
these phonemes by the vocal tract of a person whose first language is
not English but is, in our case, Portuguese. We therefore used a
database that is used for the output of Portuguese, in particular
br1 the database for Brazilian Portuguese for MBROLA.
There is a problem with this way of thinking, in the background
section it was determined that Portuguese had less phonemes than
English, therefore there are certainly a number of phonemes MBROLA is
not able to produce using the br1 database. Therefore it is necessary
to translate the phonemes. The following diagram illustrates a
solution to the problem.
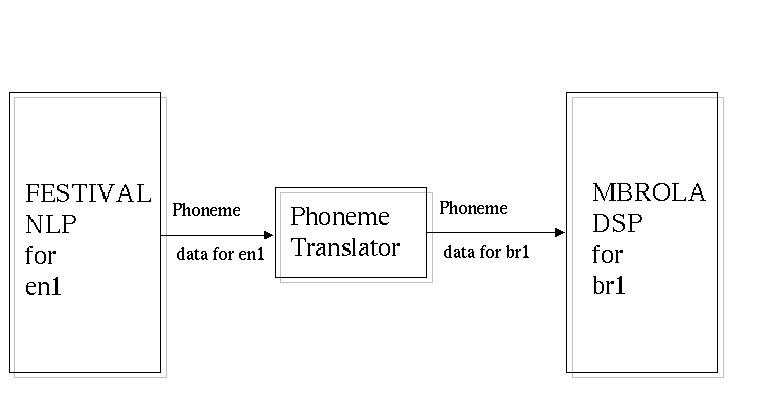
Illustration
2 Accent module
The phoneme translator filters the phonemes only accepting those
that can be used by MBROLA for the br1 database.
Alternatives
Another solution to the problem would be to modify the database in
order for it to accept en1 phonemes. Unfortunately MBROLA databases
have a proprietary format and cannot be easily modified.
A different approach would be to modify the rules in the NLP in
order to produce output for br1. This solution would be more complex
than the previous two because it involves research related to the
exact procedures involved in text to phoneme conversion.
Information
on phonemes
To be able to write an appropriate translator it is necessary to
know which are the phonemes present in the source (en1) and target
(br1) databases (See Appendix). The documentation that is included
with each database provides information on the supported phoneme set
along with the notations used for each phoneme. The br1 database does
not adhere completely to any particular standard, most of the
phonemes comply with the Speech Assessment Methods Phonetic
Alphabet (SAMPA) but there are exceptions. Therefore this is a
problem that had to be dealt with when translating the phonemes.
Mike Hamilton's web site (Cross-language synthesis with MBROLA,
2000) had some sample code written in PERL, which was of great use in
particular for dealing with certain aspects of the translation such
as elision.
The next step was to determine which phonemes were to be used when
they did not exist in the target database. This was obtained from the
book that was suggested by Schutz (2001 May 5 ) written by Azevedo
(1981). The book concentrates more on the mapping of phones from
Portuguese to English, but there are chapters dedicated to Portuguese
phones on the one hand and to English phones on the other. This was
completed with Schutz's work on correspondence of vowels (Schutz,
2001a) and that of the correspondence of consonants (Schutz, 2001b).
Detailed
Procedure
To add an accent to the TH the approach suggested by Mike Hamilton
on his web site (Cross-Language synthesis with MBROLA, 2000) and
through E-mail (Hamilton, M. 2001 March 21) is to take the phoneme
output of an English NLP and "map each English phoneme to the
nearest sounding phoneme in the other language" then finally
provide for the cases where the English phonemes are unpronounceable
in the target language.
Then there is the problem that certain phoneme sequences cannot be
rendered by br1, this problem is solved by separating the tow
offending phonemes with a @ phoneme.
For example "em" cannot follow "rr" so if this
sequence is found amongst the phonemes being parsed an @ is
intercalated. Thus the sequence
em 20 25 110
rr 12
becomes:
em 20 25 110
@ 10
rr 12
This can be rendered by MBROLA using the br1 database. The first
number is the duration of the phoneme. The next pair of numbers
correspond to the location of the pitch in the phoneme and the pitch
value, there can be several of these pairs:
<phoneme> <duration> <location of pitch> <pitch
value>
During testing of the standalone program it was found that words
starting with the letter h
and followed by a vowel other than i were
pronounced as a y,
giving sentences like "yeaven knows yow" instead of "heaven
knows how" therefore "h" phonemes are never output by
the accent module. This does not affect the output significantly
given that "h" is a relatively silent phoneme.
The result of the mapping of all the other phonemes can be found
in the appendix.
The accent module takes in a filename that contains all the
phonemes that have been modified by the emotion module, creates a
temporary file where all the output will be directed then the input
file is overwritten with the output file.
Accent
intensity
One of the requirements of the project was for the user to be able
to specify the intensity of the accent to be introduced. In the
mapping performed previously we were trying to map to phonemes that
were the closest to those in the target language, this gives us a
voice with the lowest possible accent using the br1 database. In
order to increase the intensity of L1 interference we will map the
en1 phonemes to phonemes that would be used by a person speaking
English with a strong Brazilian accent. Moreover the length of the @
phoneme being introduced is now increased in order to give an "euh"
effect at the end of a word.
MRPA
and SAMPA
The FESTIVAL NLP outputs phonemes that are in Machine Readable
Phonetic Alphabet (MRPA), the emotion module accepts this input, when
the accent module gets MRPA phonemes it converts them to SAMPA and
then applies the necessary modifications.
For this reason it is no longer necessary to specify the
conversion on the command line for MBROLA , because MBROLA accepts
input in SAMPA. This too applies to br1 that accepts a modified
version of SAMPA (see Appendix A). In fact the conversion switch must
not be included because of the differences between the phoneme set of
br1 and SAMPA. For example the en1 database requires the "y"
phoneme of MRPA to be converted into the SAMPA equivalent which is a
"j", but br1 contains a "y" as part of it's
phoneme set so if the MRPA to SAMPA conversion is present in the
command line to MBROLA, all "y" phonemes are converted to
"j" which is undesirable.
Integration to the Talking Head
The accent module was integrated to the TH just before the WAV
file is created. The temporary file created by the emotion module is
taken and modified as described in section 3.3.4. The WAV file is
then created and played by the TH.
It was found that the default speed at which the talking head
spoke was too fast to be understandable, therefore the time factor
was modified. This was done by multiplying the existing time factor
by 1.2, rather than just setting it to this value, in order to
preserve any modifications by the emotion module.
Other modifications were necessary in order to account for the
extra attributes, new class members were added, this was relatively
straightforward as it was only a question of extending the existent
speaker tag to accommodate for the extra "accent" and
"accentint" attributes. All files modified are listed in
the appendix. Comments were added within the code to specify what
exactly has been modified. Moreover the GNU revision control system
(RCS) was used to keep track of modifications and to allow for
reverting to a previous working version of the code.
Testing and Analysis
Testing
The accent module was first developed as a standalone program and
tested as such. Once the module was ready it was integrated to the TH
where further testing was performed.
Testing was used to determine if no disallowed sequences of
phonemes were left out. The only way to discover whether any such
sequences had been left out was through extensive testing given that
there is no mention of this in the documentation accompanying the br1
database.
Testing was also used to determine whether the output was
understandable or not.
Test Data
There are several XML test files available in the
"TalkingHeads/server" folder:
long.xml: Contains two relatively long sentences and its'
purpose is to test the whether the with the accent people can still
understand or have an idea of what is being said.
short.xml: Contains short sentences and is aimed at testing
whether short utterances are more understandable than long ones.
intensity.xml: Contains examples of sentences pronounced
with high and low intensity of accent
Not all the test data has been included because not all of it was
kept. In particular the data used for creating strong and weak
accents and the data for phoneme sequences.
Analysis and results
An informal evaluation was carried out and it was found that most
people when listening to the result of a sentence, to which an accent
was added, had more difficulty understanding the meaning of the
sentence when the sentence was long than when it was shorter. When
the sentence was long most people could understand only a few words.
Some people had trouble realising that the sentence was actually in
English and said that it sounded like German. These persons were not
together when they listened to the various sentences but were still
able to come up with the same remark.
At normal speed, the sentences are hard if not nearly impossible
to understand, but if the speed of delivery of the sentence is
reduced it becomes much easier to understand the examples.
The fact that the accented voice is not very clear is partly due
to the quality of the br1 database. There are three databases
available for Brazilian Portuguese, but br2 and br3 when tested, were
found to be of poor quality in regards to the clarity of the
utterances produced. The br1 database was found to be the best of the
three databases for Brazilian Portuguese.
This is not a big problem because one of the uses of the accent
could be precisely to make the transfer of information more
difficult. For example if the TH wanted to give a hint to the user
(assignment hint, important detail leading to the suspect of a
murder) but make it a bit obscure it could use an accent.
Known Faults
Synchronisation
When the TH speaks with an accent, the lips stop moving before the
end of the sentence. This occurs approximately after 75% of the
utterance has been output to the sound card. In some cases, the head
stops moving and shortly after, the utterance is interrupted.
This is due to the fact that the accent module adds extra phonemes
like the @ phoneme. In addition to that when it translates certain
phonemes, instead of having a one-to-one mapping of the phoneme there
is a one-to-two mapping. These elements contribute to the lengthening
of the utterance at the phoneme level. Finally when the phonemes are
converted to a WAV file, MBROLA is run with a time factor of at least
1.2. The problem is that the addition of the accent is made after the
duration of the utterance has been calculated.
To remedy to this,the integration would have to be done before the
calculation of the length of the utterance is made. The problem is
that at this stage all the phonemes are in memory in the form of C++
objects, thus requiring the accent module to be written in C++ to
handle objects instead of the current implementation which is in C
and manipulates files.
Possible problems
Problems may arise if a sequence of phonemes that is not accepted
by the br1 database is encountered in the input file. Given that the
only way to find these sequences is through trial and error, there
may be cases that may have been overlooked during the exploration
stage of the development.
In such a case MBROLA will output a message specifying the
offending phonemes, these will need to be added to the list of elides
in the program .
Future Work
Different database for Portuguese
The implementation could be modified in order to work with another
Portuguese database, like a new one of better quality if any are made
available. The pt1 database for a female voice was also tested and
was found to be of equally poor quality as br2 and br3.
Different Accent
Other foreign accents could be added to the TH, any language can
be used, the only difficulty lies in finding information on how to
perform the mapping. Moreover there may be other language dependent
aspects that may need to be taken into consideration and that are not
relevant for Portuguese. For example a person with an Asian accent
may sound as if the words being pronounced are chopped at the end.
Integration
Further work would include integration of the accent module to the
talking head in order for its' modifications to be taken into account
when the length of the utterance is being calculated.
Grammar
When foreigners speak if they don't have good knowledge of the
language being spoken, often the grammar will be incorrect. If this
could be replicated in the utterances produced it would provide more
credibility to the fact that the TH is representing a foreigner.
Conclusion
In the background section we went through the causes of accents in
spoken language and determined from the literature that the main
cause was L1 interference. This was replicated in the project by
using an NLP to produce phonemes that would be used by a DSP using an
English database, except that instead of using an English database, a
Brazilian one was used. The output of the NLP cannot be fed in
directly to the DSP therefore a translation module was necessary.
This is not the only role of the translation module, it is also there
to make modifications to the phonemes depending on whether a strong
accent or a weak accent is desired. Once the module was functional
and tested it was integrated to the TH.
Integrating the module to the TH required modifying the XML-based
SML (Speech Markup Language).This was straightforward given that XML
is easy to extend through the DTD, easy to understand being based on
a plain text format and robust. The fact that it requires strict
validation makes it a good accessory for programming.
The TH is an advanced interface for human to machine communication
with its' close to human appearance and emotion enhanced voice. The
addition of an accent takes it one step closer to realistic human
representation.
This project has shown that it is possible to produce an accented
voice using text input and how this can be accomplished using current
TTS technology. It has also shown that XML can be easily extended.
Unfortunately it falls a bit short of showing that this new feature
can be added to TH relatively easily given that the integration is
imperfect.
Reference List
Azevedo,
M. (1981). A Contrastive Phonology of Portuguese and
English. Washington D.C.:
Georgetown University Press.
Cross-language
synthesis with MBROLA [Online] Available:
http://www.hamilton.net.au/mbrola.html
[2000 June 22]
Dutoit,
T. (1997). An Introduction to Text-to-Speech Synthesis,
Kluwer Academic Publishers.
Hill, J. (1970): "Foreign Accents, Language Acquisition and
Cerebral Dominance Revisited." Language Learning, 20, pp.247-248
Lado, Robert (1968). Contrastive Linguistics in a Mentalistic
Theory of Language Learning. Georgetown University: Round Table on
Languages and Linguistics 1968. Edited by James E. Alatis. Washington
D.C.:Georgetown University Press. 123-135.
Mbrola Homepage [Online]
http://tcts.fpms.ac.be/synthesis/mbrola/mbrola_entrypage.html
[September 2001]
Major,
R.C. (1987). Foreign Accent: Recent Research and Theory.
International review of applied linguistics in language teaching 25
(2), 185-202.
www.yourdictionary.com
Homepage [Online] Available:
http://www.yourdictionary.com
[October 2001]
Multimedia Description Schemes Group (March 2001).Text
of 15938-5 FCD Information Technology - Multimedia Content
Description Interface - Part 5 Multimedia Description Schemes.
ISO/IEC JTC 1/SC 29/WG 11/N3966, Singapore
Schutz, R. (2001 May 5) Re: Attn: Ricardo Schutz, Projecto
Interface. E-mail to C.S. de Souza ( desouza@cs.curtin.edu.au ).
Schutz, R. (2001a) A Questão das Vogais - English and
Portuguese Vowels Phonemes Compared [Online] Available:
http://www.sk.com.br/sk-voga.html [2001 June].
Schutz, R. (2001b) As Consoantes em Inglês e Português
- English and Portuguese Consonant Phonemes Compared [Online]
Available: http://www.sk.com.br/sk-conso.html [2001 June].
Scovel, T.(1969): "Foreign Accents, Language Acquisition, and
Cerebral Dominance." Language Learning, 19, pp.245-253.
Stallo, J. (2000) "Simulating emotional speech for a talking
head", Honours Dissertation, Curtin University of Technology,
Perth, Australia.
VHML Homepage [Online] Available: http://www.vhml.org/ [2001, May
22].
Appendix A: Phonemes in br1
BBBBBBB RRRRRRRRR 1
B B R R 11
B B R R 1
B B R R 1
BBBBBBB RRRRR 1
B B R R 1
B B R R 1
B B R R 1
BBBBBBB R R 11111
release 2.021
--------------------------------------------------------------
Table of Contents
--------------------------------------------------------------
1.0 A brief description of the BR1
database
2.0 Distribution
3.0 Installation, and tests
4.0 Acknowledgments
--------------------------------------------------------------
1.0 A brief description of BR1
--------------------------------------------------------------
BR1 is a Brazilian Portuguese diphone
database provided in the
context of the MBROLA project
(see http://tcts.fpms.ac.be/synthesis).
It provides a Portuguese male voice to be
used with the MBROLA program.
Input files use the following diphone
representations, that diverges
from SAMPA in some points:
PHONEME EXAMPLE TRANSCRIPTION SAMPA
EQUIVALENT
b barco "ba r2 ku b
k com "k om k
d doce "dose d
g grande "gr am de g
p pai "pai p
t taco "tako t
f fácil "fasiw f
v vinho "vi nh o v
j jato "jato Z
s sala "sala s
s2 casca "ka s2 ka ---
x chave "xave S
z aza "aza z
m mesmo "me s2 mo m
n nunca "n um ka n
nh galinha ga"li nh a J
l lanche "l am xe l
lh alho "a lh o L
r puro "puro r
r2 arpa "a r2 pa ---
rr torre "to rr e R
a vale "vale a
@ tamanho ta "m@ nh o 6
am campanha k am "pa nh a ---
e pêra "pera e
ee quero "k ee ro E
em quente "k em te e~
i pico "piko i
im brinco "br im ko i~
o tolo "tolo o
oo bola "b oo la ---
om ombro "om bro o~
u duro "duro u
um algum aw"g um u~
y mais "may s2 y
w mau "maw w
_ silence
--------------------------------------------------------------
2.0 Distribution
--------------------------------------------------------------
This distribution of mbrola contains the
following files :
br1 : the database itself
br1.txt : This file
br1sampa.set : a SAMPA phoneme set
license.txt : must read before using
the database
TEST/teste.pho: a sample pho file
TEST/test-sampa.pho: a sample pho file
using SAMPA alphabet
Additional languages and voices, as well
as other example command
files, are or will be available in the
context of the MBROLA
project. Please consult the MBROLA
project homepage :
http://tcts.fpms.ac.be/synthesis
Registered users will automatically be
notified of the availability
of new databases. To freely register,
simply send an email to
mbrola-interest-request@tcts.fpms.ac.be
with the word 'subscribe'
in the message title.
--------------------------------------------------------------
3.0 Installation and Tests
--------------------------------------------------------------
If you have not copied the MBROLA
software yet, please consult
the MBROLA project homepage and get it.
Copy br1.zip into the mbrola directory
and unzip it :
unzip br1.zip (or pkunzip on PC/DOS)
(don't forget to delete the .zip file
when this is done)
Try
mbrola br1 TEST/teste.pho test.wav
or
mbrola br1 br1sampa.set
TEST/test-sampa.pho test.wav
to create a sound file. In this example
the audio file follows
the RIFF Wav format. But depending on the
extension test.au, test.aif,
or test.raw you can obtain other file
formats. Listen to it with your
favorite sound editor, and try other
command files (*.pho) to have
a better idea of the quality of speech
you can synthesize with the
MBROLA technique.
On Unix systems you can pipe the audio
ouput to the sound player as
on a HP : mbrola es1 test.pho - | splayer
-srate 16000 -l16
Also refer to the readme.txt file
provided with the mbrola
software for using it.
--------------------------------------------------------------
4.0 Acknowledgements
--------------------------------------------------------------
I would like to thank Vincent Pagel for
his attention
and fast work in preparing the database.
--------------------------------------------------------------
Denis R. Costa: Computer Science student
at University
of São Paulo (USP) and
Development Director at MicroPower
Software.
e-mail: dcosta@ams.com.br, for questions
concerning the
database br1.
e-mail: mbrola@tcts.fpms.ac.be, for
general information,
questions on the installation of software
and databases.
Appendix B: Phonemes in en1
EEEEEE N N 1
E NN N 1 1
E N N N 1 1
E N N N 1
EEEE N N N 1
E N NN 1
E N N 1
E N N 1
EEEEEEE N N 1111111 release
980910
Faculte Polytechnique de Mons (FPMs)
Copyright (c) 1997
All Rights Reserved.
(The original ROGER diphone database
belongs to :
Centre for Speech Technology Research
University of Edinburgh, UK
Copyright (c) 1996,1997
All Rights Reserved.)
------------------------------------------------------------
Table of Contents
------------------------------------------------------------
1.0 License and disclaimer
2.0 A brief description of the EN1
database
3.0 Distribution
4.0 Installation, and tests
5.0 Acknowledgments
------------------------------------------------------------
1.0 License and disclaimer (FPMs)
------------------------------------------------------------
This mbrola database is being
provided to "You", the
licensee, by the Faculte Polytechnique
de Mons - mbrola
team, the "Author of the Mbrola
Database", under the
following license.
By obtaining, using and/or copying this
database, you agree
that you have read, understood, and will
comply with these
terms and conditions :
Terms and conditions on the use of EN1
--------------------------------------
Permission is granted to use the MBROLA
en1 encoding of the
Roger database for synthesizing speech
with and only with
the Mbrola program made available from
the MBROLA project
www homepage :
http://tcts.fpms.ac.be/synthesis/mbrola.html
following the terms and conditions on the
use of the Mbrola
program.
Terms and conditions for the distribution
of EN1
------------------------------------------------
The distribution of this database is
submitted to the same
terms and conditions as the ones
imposed by University of
Edinburgh on the use and distribution of
the ROGER database
in an encoded form:
"Permission to use, copy, modify,
distribute this database
for any purpose is hereby granted
without fee, subject to
the following conditions:
1. Redistributions retain the above
copyright notice,
this list of conditions and the
following disclaimer.
2. Redistributions in an encoded form
must reproduce the
above copyright notice, this list
of conditions and
the following disclaimer in the
documentation and/or
other materials provided with the
redistribution.
3. Neither the name of the University
nor the names of
contributors to this work may be
used to endorse or
promote products derived from this
software without
specific prior written permission."
In addition, the distribution of this
database is submitted
to the same terms and conditions as
the ones imposed by
Faculte Polytechnique de Mons on the
distribution of the
Mbrola program, in so far as they do
not contradict the
terms and conditions quoted above.
This database may therefore be
copied and distributed
freely, provided that this notice is
copied and distributed
with it.
Disclaimer
----------
THIS MBROLA DATABASE CARRIES NO
WARRANTY, EXPRESSED OR
IMPLIED. THE USER ASSUMES ALL RISKS,
KNOWN OR UNKNOWN,
DIRECT OR INDIRECT, WHICH INVOLVE THIS
DATABASE IN ANY WAY.
IN PARTICULAR, THE AUTHOR OF THE MBROLA
DATABASE DOES NOT
TAKE ANY COMMITMENT IN VIEW OF ANY
POSSIBLE THIRD PARTY
RIGHTS.
Additionally :
THE UNIVERSITY OF EDINBURGH AND THE
CONTRIBUTORS TO THIS
WORK DISCLAIM ALL WARRANTIES WITH REGARD
TO THIS SOFTWARE,
INCLUDING ALL IMPLIED WARRANTIES OF
MERCHANTABILITY AND
FITNESS, IN NO EVENT SHALL THE
UNIVERSITY OF EDINBURGH NOR
THE CONTRIBUTORS BE LIABLE FOR ANY
SPECIAL, INDIRECT OR
CONSEQUENTIAL DAMAGES OR ANY DAMAGES
WHATSOEVER RESULTING
FROM LOSS OF USE, DATA OR PROFITS,
WHETHER IN AN ACTION OF
CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
ACTION, ARISING OUT
OF OR IN CONNECTION WITH THE USE OR
PERFORMANCE OF THIS
WORK.
------------------------------------------------------------
2.0 A brief description of EN1
------------------------------------------------------------
EN1 release is a British English
diphone database
provided in the context of the MBROLA
project :
http://tcts.fpms.ac.be/synthesis/mbrola.html
It provides a British English male voice
(known as "RogerÆs
voice") to be used with the MBROLA
program. It has been
built from the original Roger diphones
made available by
CSTR, University of Edinburgh, as part of
their generic text-
to-speech system FESTIVAL :
http://www.cstr.ed.ac.uk/projects/festival.html
Input files use the SAMPA phonetic
notation, as adopted in
other MBROLA databases. Below is a
list of the English
speech sounds it accounts for, with
examples. We also give
the correspondence with the MRPA
phonetic notation used in
the original distribution of RogerÆs
voice in the FESTIVAL
TTS system.
MRPA SAMPA
Example
p p put
b b but
t t ten
d d den
k k can
m m man
n n not
l l like
r r run
f f full
v v very
s s some
z z zeal
h h hat
w w went
g g game
ch tS chain
jh dZ Jane
ng N long
th T thin
dh D then
sh S ship
zh Z
measure
y j yes
ii i: bean
aa A: barn
oo O: born
uu u: boon
@@ 3: burn
i I pit
e e pet
a { pat
uh V putt
o Q pot
u U good
@ @ about
ei eI bay
ai aI buy
oi OI boy
ou @U no
au aU now
I@ I@ peer
e@ e@ pair
u@ U@ poor
MRPA also actually defines two allophones
of [l] : a "light"
one [l], as in "list", and
a "dark" one [ll], as in
"festival". We have used the
character found in the IPA-SAM
Truetype font [5].
ll 5 bolt
Additionally, the notation for silence is
the one used in
previous mbrola databases : _ (MRPA uses
#).
However, in order to maintain a strict
compatibility with
the MRPA notation, and to allow any
other notation to be
used as well, we have included in the
distribution of en1 a
configuration file which performs
automatic MRPA to SAMPA
phoneme mapping (as accepted by the
latest version of
mbrola; see below).
Notice finally that there is no support
for SAMPA's glottal
stop (?, as in "network"
[ne?w3:k]) nor for the voiceless
velar fricative (x, as in "loch"
[lQx]).
Limitations:
-----------
In the FESTIVAL distribution of Roger's
voice, not all 2116
diphones (i.e. 46x46) are available.
For reasons of compactness, some diphones
(like e-dZ and e-
d, for instance) have been mapped into a
single unit. This
should not have a major influence
on the quality of
synthetic speech.
Notice also that not all diphones are
possible in English
(like f-ng, for instance). However,
in order to avoid
problems when trying to synthesize
such impossible
combinations, we have systematically
mapped impossible
diphones to 3:-@ (as done by FESTIVAL
itself).
------------------------------------------------------------
3.0 Distribution
------------------------------------------------------------
This distribution of mbrola contains the
following files :
en1 : the database itself
en1mrpa : a configuration file,
which can follow en1
on the command line, and
enables automatic
phoneme mapping for
use with the MRPA
notation.
readme.txt : this file
and several example .PHO files :
mbrola.pho : a small introduction to
mbrola
mbrolamr.pho: same thing, MRPA
notation
euler.pho : a famous quotation by
Swiss mathematician
Leonhard Euler
eulerfr.pho : same thing in French
with an English accent
tobe.pho : mbrola metaphysics
Additional languages and voices, as well
as other example
command files, are or will be available
in the context of
the MBROLA project. Please consult
the MBROLA project
homepage :
http://tcts.fpms.ac.be/synthesis/mbrola.html
Registered users will automatically be
notified of the
availability of new databases. To
freely register, simply
send an email to
mbrola-interest-request@tcts.fpms.ac.be
with the word 'subscribe' in the message
title.
------------------------------------------------------------
4.0 Installation and Tests
------------------------------------------------------------
If you have not copied the MBROLA
software yet, or if you
have an older version, please consult
the MBROLA project
homepage and get it.
Copy en1.zip into the mbrola directory
and unzip it :
unzip en1.zip (or pkunzip on PC/DOS)
(don't forget to delete the .zip file
when this is done)
Try
mbrola en1 euler.pho euler.wav
to create a sound file. In this
example the audio file
follows the RIFF Wav format. But,
depending on the
extension, euler.au, euler.aif, or
euler.raw, you can obtain
other file formats. Listen to it with
your favorite sound
editor, and try other command files
(*.pho) to have a better
idea of the quality of speech you can
synthesize with the
MBROLA technique.
On Unix systems you can pipe the audio
ouput to the sound
player. On a HP, for instance, do:
mbrola en1 euler.pho - | splayer
-srate 16000 -l16
Also refer to the readme.txt file
provided with the mbrola
software for using it.
You can also very easily use the
MRPA input file
eulermrp.pho :
mbrola en1 en1mrpa eulermrp.pho
euler.wav
------------------------------------------------------------
5.0 Acknowledgments
------------------------------------------------------------
We would like to thank Alan Black,
Paul Taylor, Roger
Burroughes, Alistair Conkie, and Sue Fitt
for the remarkable
contribution they have made to free
speech synthesis by
making the original Roger diphone
database freely available
without any restriction of use.
It should be noted in that respect
that mbrola-based
synthesis using en1 is fully supported by
the Festival text-
to-speech system developed at CSTR and
available at :
http://www.cstr.ed.ac.uk/projects/festival.html
(Other possible uses of the mbrola speech
synthesizer within
complete TTS systems are listed at :
http://tcts.fpms.ac.be/synthesis/mbrtts.html)
------------------------------------------------------------
The MBROLA team
Sep 1998
Faculte Polytechnique de Mons
31 Bvd Dolez
B-7000 Mons
Belgium
Tel.: +32.65.374133
Fax.: +32.65.374129
e-mail: mbrola@tcts.fpms.ac.be, for
general information,
questions on the installation of software
and databases.
Appendix C: Mapping of Phonemes from en1 to br1
|
en1 phoneme
|
br1 phoneme for weak accent
|
br1 phoneme for strong accent
|
|
aI
|
ai
|
ai
|
|
e@
|
e@
|
e@
|
|
U@
|
u@
|
u@
|
|
aU
|
au
|
au
|
|
I@
|
i@
|
i@
|
|
3:
|
ee@
|
ee@
|
|
5
|
l
|
l
|
|
p
|
p
|
p
|
|
b
|
b
|
b
|
|
t
|
t
|
t
|
|
d
|
d
|
d
|
|
k
|
k
|
k
|
|
m
|
m
|
m
|
|
n
|
n
|
n
|
|
l
|
l
|
l
|
|
r
|
r
|
r2
|
|
f
|
f
|
f
|
|
v
|
v
|
v
|
|
s
|
s
|
s
|
|
z
|
z
|
z
|
|
h
|
h
|
h
|
|
w
|
w
|
w
|
|
g
|
g
|
g
|
|
T
|
t
|
t
|
|
D
|
t
|
d
|
|
S
|
x
|
x
|
|
Z
|
z
|
z
|
|
j
|
y
|
y
|
|
e
|
e
|
ee
|
|
{
|
a
|
a
|
|
V
|
a
|
a
|
|
Q
|
o
|
o
|
|
U
|
u
|
u
|
|
@
|
@
|
@
|
|
N
|
n
|
n
|
|
I
|
i
|
im
|
|
_
|
_
|
_
|
|
#
|
#
|
#
|
|
tS
|
x
|
x
|
|
dZ
|
j
|
x
|
|
i:
|
i
|
i
|
|
A:
|
a
|
a
|
|
O:
|
oo
|
oo
|
|
u:
|
u
|
u
|
|
eI
|
e
|
e
|
|
aI
|
i
|
i
|
|
OI
|
oo
|
oo
|
|
@U
|
oo
|
oo
|
|
aU
|
oo
|
u
|
Appendix D: Code Modifications
The following files were modified in order to integrate the accent
module to the Talking Head. See within the code itself for details of
what exactly was modified. The number in brackets corresponds to the
version of the file as specified by GNU RCS (Revision Control System,
files are stored in RCS directory):
TTS_MbrolaOptions.h (1.4)
TTS_DigitalSignalProcessor.cpp (1.7)
TTS_DigitalSignalProcessor.h (1.3)
TTS_Central.cpp (1.1) Using initial version modifications
were going to be made for better integration but were not effective
TTS_Central.h (1.1) Using initial version modifications were
going to be made for better integration but were not effective
TTS_Speaker.cpp (1.4)
TTS_Speaker.h (1.6)
sml-v01.dtd (1.2)